UVM Question and Answer Part1
Companies Related Questions, Functional Verification, Uncategorized, UVM 0 CommentsWelcome to section uvm question and answer part1 ,
I will try to put around 20 to 30 questions and answer related to UVM
Lets Start
What are some of the benefits of UVM methodology?
UVM is a standard verification methodology which is getting standardized as IEEE
1800.12 standard. UVM consists of a defined methodology in terms of architecting
testbenches and test cases, and also comes with a library of classes that helps in building efficient constrained random testbenches easily.
Some of the advantages and focus of the methodology include following:
1) Modularity and Reusability – The methodology is designed as modular
components (Driver, Sequencer, Agents, Env, etc.) and this enables reusing
components across unit level to multi-unit or chip level verification as well as
across projects.
2) Separating Tests from Testbenches – Tests in terms of stimulus/sequencers are
kept separate from the actual testbench hierarchy and hence stimulus can be reused
across different units or across projects.
3) Simulator Independent – The base class library and the methodology is
supported by all simulators and hence there is no dependence on any specific
simulator.
4) Sequence methodology gives good control on stimulus generation. There are
several ways in which sequences can be developed: randomization, layered
sequences, virtual sequences, etc. This provides a good control and rich stimulus
generation capability.
5) Config mechanisms simplify configuration of objects with deep hierarchy. The
configuration mechanism helps in easily configuring different testbench
components based upon verification environment using it, and without worrying
about how deep any component is in the testbench hierarchy.
6) Factory mechanisms simplify modification of components easily. Creating each
components using factory enables them to be overridden in different tests or
environments without changing underlying code base
What are some of the drawbacks of UVM methodology?
With increasing adoption of UVM methodology in the verification industry, it should be clear that the advantages of UVM overweight any drawbacks.
1) For anyone new to the methodology, the learning curve to understand all details and the library is very steep.
2) The methodology is still developing and has a lot of overhead that cansometimes cause simulation to appear slow or probably can have some bug
Can UVM be used for SoC verification? Many of the companies use complete C based verification approach for ARM based
SoC verification. Your comment would be useful
Yes, UVM is typically used for SoC verificatio. Many companies use UVM in a
SystemVerilog verification environment combined with software-based verification (e.g. using an ARM instruction-set
simulator)
What is factory automation? How is it different in building a conventional SV testbench
The factory is a mechanism that gives you more flexibility when instantiating components in the verification environment or
generating stimulus. The factory allows you to override the types of objects that are created by existing verification code
without needing to modify the original source code.
what is the super class of the current class?
The super-class is the class that the current class “extends”. So the superclass of my_test is uvm_test
What is the concept of Transaction Level Modelling?
Transaction level Modelling (TLM) is an approach to model any system or design at a higher level of abstraction. In TLM, communication between different modules is modeled using Transactions thus abstracting away all low level implementation details. This is one of the key concepts used in verification methodologies to increase productivity in terms of modularity and reuse. Even though the actual interface to the DUT is represented by signal-level activity, most of the verification tasks such as generating stimulus, functional checking, collecting coverage data, etc. are better done at transaction level by keeping them independent of actual signal level details. This helps those components to be reused and better maintained within and across projects
What are TLM ports and exports?
In Transaction Level Modeling, different components or modules communicate using transaction objects. A TLM port defines a set of methods (API) used for a particular connection while the actual implementation of these methods are called TLM exports. A connection between the TLM port and the export establishes a mechanism of communication between two components. Here is a simple example of how a producer can communicate to a consumer using a simple TLM port. The producer can create a transaction and “put” to the TLM port, while the implementation of “put” method which is also called TLM export would be in the consumer that reads the transaction created by producer, thus establishing a channel of communication.
What are TLM FIFOs?
A TLM FIFO is used for Transactional communication if both the producing component and the consuming component need to operate independently. In this case (as shown below), the producing component generates transactions and “puts” into FIFO, while the consuming component gets one transaction at a time from the FIFO and processes it.
What is the difference between a get() and peek() operation on a TLM
fifo? The get() operation will return a transaction (if available) from the TLM FIFO and also removes the item from the FIFO. If no items are available in the FIFO, it will block and wait until the FIFO has at least one entry. The peek() operation will return a transaction (if available) from the TLM FIFO without actually removing the item from the FIFO. It is also a blocking call which waits if FIFO has no available entry.
What is the difference between a get() and try_get() operation on a TLM fifo?
get() is a blocking call to get a transaction from TLM FIFO. Since it is blocking, the task get() will wait if no items are available in the FIFO stalling execution. On the other hand, try_get() is a nonblocking call which will return immediately even if no items are available in the FIFO. The return value of try_get() indicates if a valid item is returned or not.
What is the difference between analysis ports and TLM ports? And what is the difference between analysis FIFOs and TLM FIFOs? Where are the analysis ports/FIFOs used?
The TLM ports/FIFOs are used for transaction level communication between two components that have a communication channel established using put/get methods. Analysis ports/FIFOs are another transactional communication channel which are meant for a component to distribute (or broadcast) transaction to more than one component.TLM ports/FIFOs are used for connection between driver and sequencer while analysis ports/FIFOs are used by monitor to broadcast transactions which can be received by scoreboard or coverage collecting components
What is the difference between a sequence and sequence item?
A sequence item is an object that models the information being transmitted between two components (sometimes it can also be called a transaction). For Example: consider memory access from a CPU to the main memory where CPU can do a memory read or a memory write, and each of the transaction will have some information like the address, data and read/write type. A sequence can be thought of a defined pattern of sequence items that can be send to the driver for injecting into the design. The pattern of sequence items is defined by how the body() method is implemented in sequence. For Example: Extending above example, we can define a sequence of 10 transactions of reads to incremental memory addresses. In this case, the body() method will be implemented to generate sequence items 10 times, and send them to driver while say incrementing or randomizing address before next item.
What is the difference between a uvm_transaction and a uvm_sequence_item?
uvm_transaction is the base class for modeling any transaction which is derived from uvm_object . A sequence item is nothing but a transaction that groups some information together and also adds some other information like: sequence id (id of sequence which generates this item), and transaction id (the id for this item), etc. It is recommended to use uvm_sequence_item for implementing sequence based stimulus.
What is the difference between copy(), clone(), and create() method in a component class?
1) The create() method is used to construct an object.
2) The copy() method is used to copy an object to another object.
3) The clone() method is a one-step command to create and copy an existing
object to a new object handle. It will first create an object by calling the create()
method and then calls the copy() method to copy existing object to the new handle.
Explain the concept of Agent in UVM methodology.
UVM agent is a component that collects together a group of other uvm_components focused around a specific pin-level interface for a DUT. Most of the DUTs have multiple logical interfaces and an Agent is used to group all: driver, sequencer, monitor, and other components, operating at that specific interface. Organizing components using this hierarchy helps in reusing an “Agent” across different verification environments and projects that have same interface. Following diagram shows usually how a group of components are organized as agent.
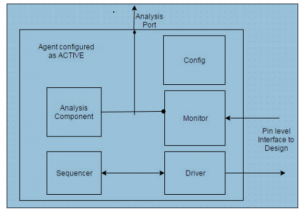
What all different components can a UVM agent have?
As explained in previous question, an agent is a collection of components that are grouped based on a logical interface to the DUT. An agent normally has a driver and a sequencer to drive stimulus to the DUT on the interface on which it operates. It also has a monitor and an analysis component (like a scoreboard or a coverage collector) to analyze activity on that interface. In addition, it can also have a configuration object that configures the agent and its components.
What is the difference between get_name() and get_full_name()
methods in a uvm_object class? The get_name() function returns the name of an object, as provided by the name argument in the new constructor or set_name() method. The get_full_name() returns the full hierarchical name of an object. For uvm_components, this is useful when used in print statements as it shows the full hierarchy of a component. For sequence or config objects that don’t have a hierarchy, this prints the same value as a get_name()
How is ACTIVE agent different from PASSIVE agent?
An ACTIVE agent is an agent that can generate activity at the pin level interface on which it operates. This means, the components like driver and sequencer would be connected and there would be a sequence running on it to generate activity. A PASSIVE agent is an agent that doesn’t generate any activity but can only monitor activity happening on the interface. This means, in a passive agent the driver and sequencer will not be created. An Agent is normally configured ACTIVE in a block level verification environment where stimulus is required to be generated. Same agent can be configured PASSIVE as we move from block level to chip level verification environment in which no stimulus generation is needed, but we still can use same for monitoring activity in terms of debug or coverage.
How is an Agent configured as ACTIVE or PASSIVE?
UVM agents have a variable of type UVM_ACTIVE_PASSIVE_e which defines whether the agent is active (UVM_ACTIVE) with the sequencer and the driver constructed, or passive (UVM_PASSIVE) with neither the driver nor the sequencer constructed. This parameter is called active and by default it is set to UVM_ACTIVE. This can be changed using set_config_int() while the agent is created in the environment class. The build phase of the agent should then have the code as below to selectively construct driver and sequencer.
function void build_phase(uvm_phase phase);
if(m_cfg.active == UVM_ACTIVE) begin
//create driver, sequencer
end
endfunction
What is a sequencer and a driver, and why are they needed?
A Driver is a component that converts a transaction or sequence item into a set of pin level toggling based on the signal interface protocol. A Sequencer is a component that routes sequence items from a sequence to a driver and routes responses back from driver to sequence. The sequencer also takes care of
arbitration between multiple sequences (if present) trying to access driver to stimulate the design interface. These components are needed as in a TLM methodology like UVM, stimulus generation is abstracted in terms of transactions and the sequencer and driver are the components that route them and translate them to actual toggling of pins.
What is the difference between a monitor and a scoreboard in UVM?
A monitor is a component that observes pin level activity and converts its observations into transactions or sequence_items. It also sends these transactions to analysis components through an analysis port. A scoreboard is an analysis component that checks if the DUT is behaving correctly. UVM scoreboards use analysis transactions from the monitors implemented inside agents.
Which method activates UVM testbench and how is it called?
The run_test() method (a static method) activates the UVM testbench. It is normally called in an “initial begin … end” block of a top level test module, and it takes an argument that defines the test class to be run. It then triggers construction of test class and the build_phase() will execute and further construct Env/Agent/Driver/Sequencer objects in the test bench hierarchy.
What steps are needed to run a sequence?
There are three steps needed to run a sequence as follows:
1) Creating a sequence. A sequence is created using the factory creates method as shown below: my_sequence_c seq;
seq = my_sequence_c::type_id::create(“my_seq“)
2) Configuring or randomizing sequence. A sequence might have several data
members that might need configuration or randomization. Accordingly, either
configure values or call
seq.randomize()
3) Starting a sequence. A sequence is started using sequence.start() method. The
start method takes an argument which is the pointer to the sequencer on which
sequence has to be run. Once the sequence is started, the body() method in the
sequence gets executed and it defines how the sequence operates. The start()
method is blocking and returns only after the sequence completes execution.
Explain the protocol handshake between a sequencer and driver?
The UVM sequence-driver API majorly uses blocking methods on sequence and driver
side as explained below for transferring a sequence item from sequence to driver and
collecting response back from driver.
On the sequence side, there are two methods as follows:
1) start_item(<item>): This requests the sequencer to have access to the driver
for the sequence item and returns when the sequencer grants access.
2) finish_item(<item>): This method results in the driver receiving the sequence
item and is a blocking method which returns only after driver calls the item_done()
method.
On the driver side,
1) get_next_item(req) : This is a blocking method in driver that blocks until a
sequence item is received on the port connected to sequencer. This method returns
the sequence item which can be translated to pin level protocol by the driver.
2) item_done(req): The driver uses this nonblocking call to signal to the
sequencer that it can unblock the sequences finish_item() method, either when the
driver accepts the sequences request or it has executed it.
Following diagram illustrates this protocol handshake between sequencer and driver which is the most commonly used handshake to transfer requests and responses between sequence and driver.
Few other alternatives methods are: get() method in driver which is equivalent to calling get_next_item() along with item_done(). Sometimes, there would also be need for a separate response port if the response from driver to sequence contains more information than what could be encapsulated in the request class. In this case, sequencer will use a get_response() blocking method that gets unblocked when the driver sends a separate response on this port using put() method. This is illustrated in below diagram.
What are pre_body() and post_body() functions in a sequence? Do they
always get called?
pre_body() is method in a sequence class that gets called before the body() method of a sequence is called. post_body() method in sequence gets called after the body() method is called. The pre_body() and post_body() methods are not always called. The uvm_sequence::start() has an optional argument which if set to 0, will result in these methods not being called. Following are the formal argument of start() method in a
sequence.
virtual task start (
uvm_sequencer_base sequencer, // Pointer to sequencer
uvm_sequence_base parent_sequencer = null, // parent sequencer
integer this_priority = 100, // Priority on the sequencer
bit call_pre_post = 1); // pre_body and post_body called